
Pozwy o naruszenie praw autorskich przeciwko AI: Aktualizacja NYT vs OpenAI 2026
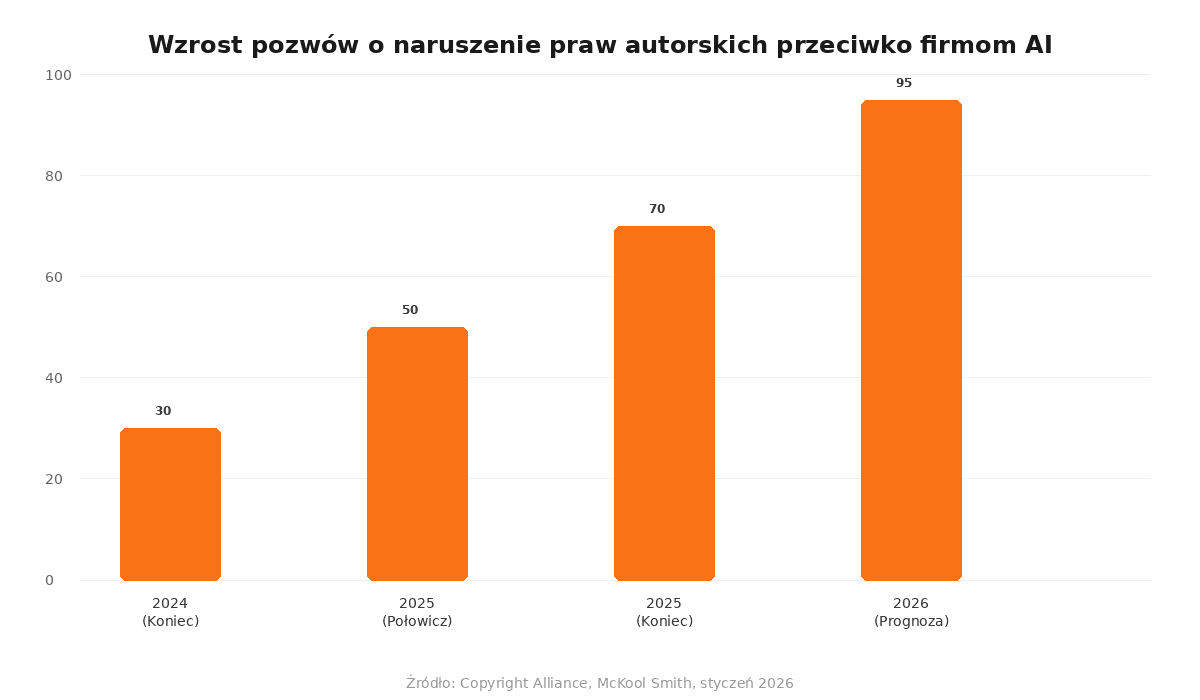
Rok 2025 przyniósł eksplozję pozwów o naruszenie praw autorskich przeciwko firmom AI. Liczba spraw wzrosła z około 30 pod koniec 2024 roku do ponad 70 w 2026 roku, a kwoty odszkodowań idą w miliardy dolarów. Co to oznacza dla przyszłości sztucznej inteligencji i twórców treści?
TL;DR: Ponad 70 pozwów o naruszenie praw autorskich przeciwko firmom AI, z których najważniejszym jest spór NYT vs OpenAI z decyzją o sprawiedliwości przewidzianą na lato 2026. Anthropic już zapłacił 1,5 miliarda USD za 482 460 nielegalnie pobranych książek, a OpenAI musi udostępnić 20 milionów logów ChatGPT. Wynik tych spraw zdefiniuje przyszłość szkolenia modeli AI.
Dlaczego liczba pozwów przeciwko AI wzrosła do ponad 70?
Liczba spraw o naruszenie praw autorskich wniesionych przeciwko firmom AI w 2025 roku więcej niż podwoiła całkowitą liczbę z końca 2024 roku — z około 30 do ponad 70 spraw (Copyright Alliance, 2026). Ta gwałtowna eskalacja wynika z rosnącej świadomości, jak firmy AI wykorzystują chronione prawem autorskim materiały do trenowania swoich modeli językowych.
W 2025 roku Sąd Rejonowy dla Północnego Dystryktu Kalifornii wydał orzeczenie w sprawie Bartz v. Anthropic, uznając szkolenie modeli językowych za „wyjątkowo” transformacyjne i kwalifikujące się jako dozwolony użytek (fair use). Jednak ta decyzja wciąż pozostawiała Anthropic na haku miliardowych odszkodowań za nielegalne pobieranie utworów z pirackich bibliotek (Copyright Alliance, 2026).

Według badania Copyright Alliance z 2026 roku, firmy AI stoją w obliczu ponad 70 pozwów o naruszenie praw autorskich, a łączna wartość roszczeń przekracza 10 miliardów dolarów. Sądy coraz częściej dopuszczają sprawy do etapu odkrycia dowodowego, co zmusza firmy AI do ujawniania danych szkoleniowych.
Co oznacza wyrok nakazujący udostępnienie 20 milionów logów ChatGPT?
W styczniu 2026 roku amerykański sędzia Sidney Stein nakazał OpenAI udostępnić powodom 20 milionów zanonimizowanych logów rozmów z ChatGPT (Nelson Mullins, 2026). To bezprecedensowa decyzja, która może ujawnić, jak często model generował treści przypominające chronione materiały.
OpenAI argumentowało, że udostępnienie tak ogromnej ilości danych naruszy prywatność użytkowników. Sąd odrzucił te zarzuty, uznając, że zanonimizowane logi są niezbędne do ustalenia zakresu naruszeń. Decyzja ta ma daleko idące konsekwencje dla wszystkich firm AI — ich wewnętrzne dane mogą zostać ujawnione w postępowaniach sądowych.
Kluczowe daty w sprawie NYT vs OpenAI:
- Grudzień 2023: NYT składa pozew przeciwko OpenAI i Microsoft
- Marzec 2025: Sędzia dopuszcza sprawę do dalszego procedowania
- Styczeń 2026: Nakaz udostępnienia 20 milionów logów ChatGPT
- Lato 2026: Przewidywana decyzja o dozwolonym użytku (summary judgment)
Jak wygląda ugoda Anthropic na 1,5 miliarda USD?
We wrześniu 2025 roku Anthropic ogłosił ugodę na 1,5 miliarda USD w sprawie Bartz v. Anthropic (Copyright Alliance, 2026). Firma zgodziła się zapłacić około 3000 USD za każdą z 482 460 książek, które nielegalnie pobrała z pirackich bibliotek Library Genesis i Pirate Library Mirror.
Ta ugoda wysyła jasny sygnał do branży AI: nawet jeśli szkolenie modeli zostanie uznane za dozwolony użytek, nielegalne pozyskiwanie danych szkoleniowych może kosztować miliardy. Wiele innych firm AI podobno korzystało z tych samych pirackich zbiorów danych.
Według dokumentów sądowych, Anthropic pobrał 482 460 książek z pirackich bibliotek, co przy odszkodowaniu około 3000 USD za książkę dało łączną kwotę ugody 1,5 miliarda USD. To najwyższa ugoda w historii sporów o prawa autorskie w branży AI.
Czy fair use ochroni firmy AI przed pozwami?
Dwie decyzje sądowe z 2025 roku dały firmom AI mieszane sygnały. W sprawie Bartz v. Anthropic sąd uznał szkolenie za „wyjątkowo” transformacyjne. Jednocześnie w sprawie Kadrey v. Meta ten sam sąd dopuścił część zarzutów do dalszego procedowania (Copyright Alliance, 2026).
Kluczowym pytaniem pozostaje kwestia „regurgitacji” — czy modele AI mogą dosłownie odtwarzać chronione treści. W sprawie NYT vs OpenAI odkrycie dowodowe wykazało, że ChatGPT potrafi generować fragmenty artykułów NYT z niemal doskonałą dokładnością, co podważa argument o transformacyjnym charakterze szkolenia.
Czynniki wpływające na ocenę fair use:
- Cel i charakter użycia — czy szkolenie jest transformacyjne?
- Rodzaj chronionego utworu — dziennikarstwo vs literatura
- Ilość wykorzystanego materiału — całe artykuły vs fragmenty
- Wpływ na rynek — czy AI konkurkuje z oryginałem?
Jakie inne sprawy czekają na rozstrzygnięcie w 2026 roku?
Oprócz NYT vs OpenAI, w 2026 roku spodziewane są decyzje w kilkunastu innych sprawach. Sprawy In re Google Generative AI, UMG v. Suno, Concord v. Anthropic i In re Mosaic LLM Litigation czekają na orzeczenia w sprawie dozwolonego użytku (Copyright Alliance, 2026).
Niemiecka organizacja GEMA, reprezentująca ponad 95 000 kompozytorów, autorskich tekstów i wydawców, wniosła pozew przeciwko OpenAI o reprodukowanie tekstów piosenek bez licencji (McKool Smith, 2025). To pierwsza duża sprawa o prawa autorskie do muzyki przeciwko firmie AI w Europie.
Jakie są perspektywy ugód i licencjonowania?
Trend ugód i partnerstw był dominujący w 2025 roku. Firmy AI i właściciele praw autorskich coraz chętniej siadają do stołu negocjacyjnego. Wiele źródeł donosi o trwających negocjacjach w sprawie In re OpenAI, która obejmuje ponad tuzin scentralizowanych spraw (Copyright Alliance, 2026).
OpenAI już podpisał umowy licencyjne z wieloma wydawcami, w tym Associated Press, Axel Springer i Financial Times. Model podziału przychodów staje się standardem branżowym, choć szczegóły finansowe pozostają poufne. To ważna zmiana w stosunku do czasów, gdy OpenAI traciło subskrybentów na rzecz konkurencji.
Co to oznacza dla twórców treści i programistów?
Dla twórców treści, wzrost liczby pozwów oznacza większą ochronę praw autorskich, ale też niepewność co do przyszłości. Niektórzy wydawcy podpisują lukratywne umowy z firmami AI, podczas gdy inni walczą w sądzie. Ta dynamika przypomina rywalizację między Anthropic a OpenAI, gdzie obie firmy poszukują zrównoważonego modelu biznesowego.
Dla programistów i firm korzystających z modeli AI, kluczowe jest:
- Dokumentowanie źródeł danych szkoleniowych
- Unikanie pirackich zbiorów danych
- Rozważenie licencjonowania treści
- Monitorowanie orzecznictwa w tej dziedzinie
Często Zadawane Pytania
Czy mogę używać modeli AI bez obawy o pozwy?
Tak, jeśli korzystasz z gotowych modeli od renomowanych dostawców. Odpowiedzialność za dane szkoleniowe spoczywa zazwyczaj na twórcy modelu. Jeśli jednak trenujesz własne modele na chronionych materiałach, powinieneś skonsultować się z prawnikiem.
Co to jest „regurgitacja” w kontekście AI?
Regurgitacja to zdolność modelu AI do dosłownego odtwarzania fragmentów danych szkoleniowych. W sprawach sądowych wykazanie regurgitacji podważa argument, że szkolenie jest transformacyjne, ponieważ model nie „uczy się” treści, ale ją zapamiętuje.
Kiedy zapadnie ostateczny wyrok w sprawie NYT vs OpenAI?
Summary judgment (decyzja o sprawiedliwości bez pełnego procesu) jest przewidywany na lato 2026 roku. Jeśli sąd nie rozstrzygnie sprawy na tym etapie, pełny proces może trwać do 2027-2028 roku.
Czy OpenAI nadal trenuje modele na treściach z internetu?
Tak, ale z większą ostrożnością. OpenAI wprowadził mechanizmy filtrowania treści chronionych prawem autorskim i podpisuje umowy licencyjne z wydawcami. Firma jednak wciąż argumentuje, że dozwolony użytek powinien obejmować szkolenie na publicznie dostępnych materiałach.
Podsumowanie
Rok 2026 będzie decydujący dla przyszłości praw autorskich w erze AI. Wynik sprawy NYT vs OpenAI może zdefiniować, czy firmy AI muszą płacić za dane szkoleniowe, czy mogą korzystać z nich bezpłatnie w ramach dozwolonego użytku. Ugoda Anthropic na 1,5 miliarda USD pokazuje, że piractwo danych szkoleniowych jest kosztowne, nawet jeśli samo szkolenie zostanie uznane za legalne.
Dla twórców treści to moment walki o swoje prawa. Dla firm AI to czas na znalezienie zrównoważonego modelu biznesowego, który szanuje prawa autorskie. Niezależnie od wyniku, rok 2026 przyniesie fundamentalne zmiany w relacjach między AI a twórcami.
Źródła: Copyright Alliance, McKool Smith, Nelson Mullins, Reuters, NPR (2025-2026)