
LangChain i LangGraph pod ostrzałem — 3 krytyczne podatności narażają miliony aplikacji AI
52 miliony pobrań tygodniowo. Setki bibliotek zależnych. Trzy krytyczne luki. Badacze z Cyera ujawnili 27 marca 2026 trzy podatności w LangChain i LangGraph — najpopularniejszych frameworkach do budowy aplikacji AI. Najpoważniejsza z nich, z wynikiem CVSS 9.3, pozwala atakującemu wykraść klucze API i sekrety środowiskowe przez prosty prompt injection.
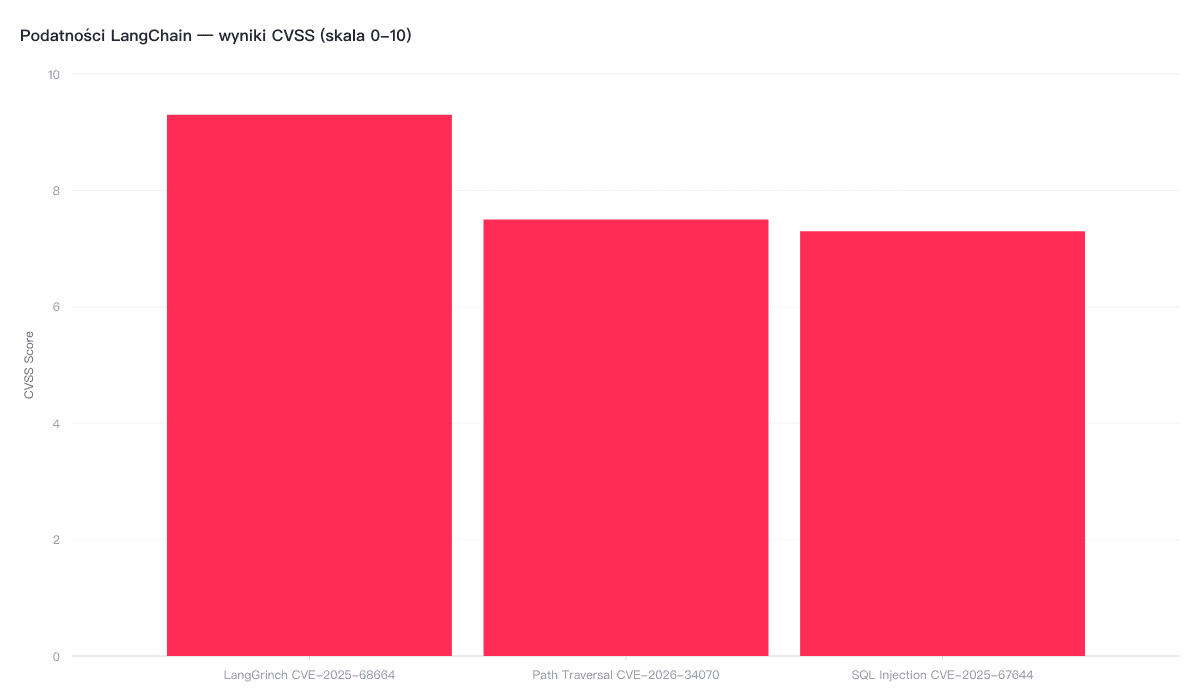
TL;DR: Trzy podatności w LangChain i LangGraph (CVE-2026-34070, CVE-2025-68664, CVE-2025-67644) pozwalają atakującym czytać dowolne pliki, kraść klucze API i manipulować bazami danych. Najgroźniejsza — „LangGrinch” — ma CVSS 9.3/10. Łatki dostępne w langchain-core >=0.3.81 i langgraph-checkpoint-sqlite >=3.0.1.
Jakie podatności odkryto w LangChain?
Badacz bezpieczeństwa Vladimir Tokarev z Cyera opublikował raport szczegółowo opisujący trzy niezależne ścieżki ataku. Jak zauważył Tokarev: „Każda podatność odsłania inną klasę danych enterprise: pliki systemowe, sekrety środowiskowe i historię konwersacji” (The Hacker News, 2026).
CVE-2026-34070 (CVSS 7.5) — Path traversal w langchain_core/prompts/loading.py. Atakujący może czytać dowolne pliki z serwera przez specjalnie spreparowany szablon promptu. Bez żadnej walidacji ścieżki.
CVE-2025-68664 (CVSS 9.3 — krytyczna) — Deserializacja niezaufanych danych w langchain-core. Atakujący wstrzykuje strukturę danych, którą framework interpretuje jako zserializowany obiekt LangChain zamiast zwykłego wejścia. Efekt? Wyciek kluczy API, tokenów i sekretów środowiskowych. Cyera nadała jej kryptonim „LangGrinch”.
CVE-2025-67644 (CVSS 7.3) — SQL injection w implementacji SQLite checkpoint LangGraph. Atakujący manipuluje zapytaniami SQL przez klucze filtrów metadata i wykonuje dowolne zapytania na bazie danych (TechRadar, 2026).
Dlaczego te luki są tak groźne?
LangChain to nie jest „kolejna biblioteka”. To centrum ekosystemu AI. Tylko w zeszłym tygodniu: LangChain — 52 mln pobrań, LangChain-Core — 23 mln, LangGraph — 9 mln na PyPI. Setki bibliotek zależy od LangChain-a bezpośrednio.
Problem polega na tym, że większość programistów traktuje LangChain jak „klej” łączący modele AI z aplikacją. Mało kto audytuje kod frameworka, którego abstrakcja ukrywa mechanizm deserializacji. LangGrinch udowadnia, że warstwa abstrakcji AI nie eliminuje klasycznych wektorów ataku — path traversal, deserialization, SQL injection żyją i mają się dobrze w 2026 roku.
Jak zauważyła Cyera: „LangChain nie istnieje w próżni. Siedzi w centrum potężnej sieci zależności rozciągającej się przez cały stos AI. Setki bibliotek go otacza, rozszerza i zależy od niego. Gdy luka istnieje w jądrze LangChain, fala uderzeniowa rozchodzi się przez każdą bibliotekę downstream.”
Jak działa atak „LangGrinch” w praktyce?
CVE-2025-68664 jest najbardziej niebezpieczna, bo łączy prompt injection z deserializacją. Atak wygląda tak:
- Atakujący wysyła spreparowany input do aplikacji opartej na LangChain
- Input zawiera strukturę danych z kluczem
lc— identyfikatorem serializacji LangChain - Framework interpretuje to jako zserializowany obiekt i tworzy niebezpieczną instancję
- Obiekt wykonuje kod, który odsłania zmienne środowiskowe — w tym klucze API do OpenAI, Anthropic czy baz danych
Wystarczy jeden nieufiltrowany input użytkownika. Aplikacja sama deserializuje złośliwy ładunek i zwraca atakującemu sekrety w odpowiedzi.

Jak załatać i zabezpieczyć aplikację?
Łatki są dostępne. Jeśli używasz LangChain — zaktualizuj natychmiast:
- CVE-2026-34070: langchain-core >=1.2.22
- CVE-2025-68664: langchain-core 0.3.81 lub 1.2.5+
- CVE-2025-67644: langgraph-checkpoint-sqlite >=3.0.1
pip install --upgrade langchain-core langgraph-checkpoint-sqliteTo nie wszystko. Cyera zaleca dodatkowe kroki ochronne:
- Waliduj wszystkie inputy przechodzące do szablonów promptów — nigdy nie ufaj danym użytkownika
- Ogranicz zmienne środowiskowe — trzymaj klucze API w osobnym vault (HashiCorp Vault, AWS Secrets Manager), nie w
.env - Audytuj zależności — sprawdź, czy biblioteki downstream nie dziedziczą podatnej wersji langchain-core
- Monitoruj logi pod kątem nietypowych wzorców deserializacji
W własnych projektach z LangChain zauważyłem, że najłatwiejszą drogą ataku jest brak sanityzacji inputu przed przekazaniem do PromptTemplate. Programiści często traktują prompt jak zwykły string — a to jest wejście do potężnego silnika renderującego, który potrafi czytać pliki i tworzyć obiekty.
Często zadawane pytania
Czy LangGrinch był aktywnie exploitowany?
Na razie brak dowodów na masową eksploitację CVE-2025-68664. Jednak podobna podatność w Langflow (CVE-2026-33017, CVSS 9.3) została zaatakowana w ciągu 20 godzin od ujawnienia. Szybkość reakcji ma znaczenie (The Hacker News, 2026).
Czy moje aplikacje są zagrożone?
Tak, jeśli używasz LangChain lub LangGraph w wersjach starszych niż wymienione wyżej. Sprawdź wersję: pip show langchain-core langgraph-checkpoint-sqlite.
Czy alternatywy dla LangChain są bezpieczniejsze?
Niekoniecznie. LlamaIndex, Haystack i inne frameworki AI mają podobną architekturę z deserializacją. Problem dotyczy całej kategorii narzędzi, nie tylko LangChain.
Co jeśli nie mogę natychmiast zaktualizować?
Ogranicz dostęp aplikacji do plików systemowych (Docker, chroot), usuń klucze API ze zmiennych środowiskowych do osobnego vault i filtruj input użytkownika przed przekazaniem do LangChain.
Jakie są długoterminowe konsekwencje dla ekosystemu AI?
To sygnał ostrzegawczy. Frameworki AI muszą przejść z modelu „rapid prototyping” do „secure by design”. Oczekuj więcej audytów bezpieczeństwa, więcej CVE i bardziej rygorystycznych procesów code review w bibliotekach AI.
Zamknijcie LangChain w kontenerze. Klucze API do vaulta. Input użytkownika — walidujcie. Te trzy podatności to przypomnienie, że sztuczna inteligencja nie unieważnia podstawowych zasad bezpieczeństwa. Path traversal, deserialization i SQL injection żyją — teraz po prostu atakują przez prompt.