
GLM-5.1 od z.ai: 744B parametrów i 2. miejsce w agentic ranking
GLM-5 miał problem: over-engineering. Nawet proste zadania dostawały pełny chain-of-thought, a wieloetapowe taski często utykały w pętlach debugowania. GLM-5.1 od z.ai rozwiązuje obie bolączki — i trafia na 2. miejsce w agentic leaderboard (NVIDIA Developer Forums, 2026).
TL;DR: GLM-5.1 to aktualizacja modelu 744B/40B MoE od z.ai, która wprowadza adaptacyjne skalowanie wnioskowania i lepsze wykonanie zadań agentowych. Zajmuje 2. miejsce w agentic ranking, ustępując tylko frontierowym modelom od Anthropic. Dostępna w GLM Coding Plan od 10 USD/miesiąc.
Czym różni się GLM-5.1 od GLM-5?
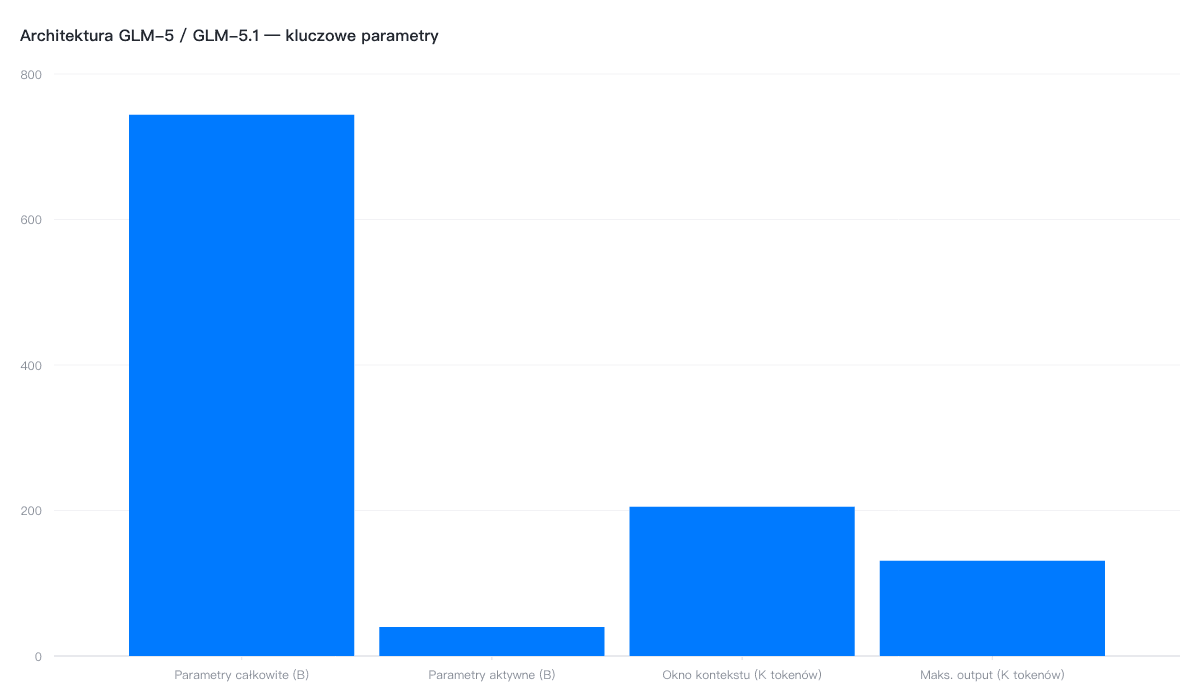
GLM-5.1 dzieli architekturę z GLM-5 — 744B parametrów całkowitych, 40B aktywnych (MoE), okno kontekstu 204 800 tokenów i maksymalny output 131 072 tokenów (z.ai Developer Docs, 2026). Różnica leży w post-trainingu: model został zoptymalizowany pod kątem zadań agentowych i workflowów kodowania.
Kluczowe zmiany dotyczą trzech obszarów. Po pierwsze, lepsze podążanie za instrukcjami — model trzyma się głównego celu i nie zbacza na boki. Po drugie, samodzielne pętle debugowania — uruchamia linter, wyłapuje błędy i iteruje, dopóki zadanie nie jest faktycznie ukończone. Po trzecie, lepsze planowanie — model analizuje pełny kontekst przed wprowadzaniem zmian, zamiast rzucać się do generowania kodu.
Dlaczego GLM-5.1 zajmuje 2. miejsce w agentic ranking?
Na agentic leaderboard GLM-5 nie miał konkretnego miejsca — był jednym z modeli open-source. GLM-5.1 wskakuje na 2. pozycję overall, co oznacza, że ustępuje tylko modelom frontierowym od Anthropic czy OpenAI (NVIDIA NIM Request, 2026).
GLM-5 bazowy osiągnął 77.8 punktów na SWE-bench Verified i 56.2 na Terminal-Bench 2.0 — najlepsze wyniki wśród modeli open-weight (arxiv.org, 2026). GLM-5.1 idzie krok dalej: nie tylko generuje poprawny kod, ale potrafi utrzymać spójność celu na długich horizonach, koordynować narzędzia i rozwiązywać zależności między krokami bez utraty kontekstu.
To definiuje Agentic Engineering — model nie tylko pisze kod, ale zarządza całym cyklem rozwoju oprogramowania: od planowania, przez implementację, po testowanie i debugowanie.
Adaptacyjne skalowanie wnioskowania — koniec nadmiernego myślenia
GLM-5 miał wadę, którą użytkownicy szybko zauważyli: over-reasoning. Nawet proste pytanie dostawało pełny chain-of-thought z analizą, co dramatycznie spowalniało pracę.
GLM-5.1 wprowadza adaptacyjne skalowanie wnioskowania. Proste zadania dostają szybką odpowiedź bez głębokiego myślenia. Złożone — pełne rozumowanie z iteracyjnym debugowaniem. Efekt jest odczuwalny: codzienne zadania w Claude Code czy Cline wykonują się zauważalnie szybciej (NVIDIA Developer Forums, 2026).
Po tygodniu pracy z GLM-5 w Claude Code mogę potwierdzić: model potrafił spędzić 3 minuty na zadaniu, które powinno zająć 30 sekund. Adaptacyjne skalowanie w GLM-5.1 to zmiana, którą programiści poczują natychmiast — nie jako metrykę benchmarkową, ale jako realną oszczędność czasu.

Jak wykorzystać GLM-5.1 w praktyce?
Model jest dostępny przez platformę z.ai w ramach GLM Coding Plan, z planami od 10 USD/miesiąc (ok. 40 zł). Kompatybilność obejmuje Claude Code, Cline, OpenClaw, Cursor i Kilo Code. Na NVIDIA NIM model jest dostępny pod identyfikatorem zai/glm-5.1 (NVIDIA Developer Forums, 2026).
Najlepsze zastosowania GLM-5.1 to długotrwałe zadania agentowe: refaktoryzacja dużych codebase’ów, generowanie testów e2e, automatyczne debugowanie i migracja kodu. Dzięki oknu kontekstu 204K tokenów model może pracować na całych plikach projektowych bez utraty spójności.
Pod względem architektury MoE (Mixture of Experts) aktywuje tylko 40B z 744B parametrów — to 5,4% całego modelu. Taki design pozwala na wydajne wnioskowanie przy zachowaniu mocy pełnego modelu.
Jakie kompromisy niesie GLM-5.1?
GLM-5.1 nie jest bez wad. Z.ai otwarcie przyznaje, że model wykazuje lekkie regresje w ogólnym czacie i QA matematycznym oraz może produkować outputy nastawione na kod nawet dla zwykłych pytań tekstowych (NVIDIA Developer Forums, 2026).
Co to oznacza w praktyce? Jeśli używasz modelu do programowania — jest to czysty upgrade. Jeśli oczekujesz wszechstronnego asystenta do rozmów, pisania tekstów i analizy danych — GLM-5.1 może rozczarować. To model celowo wyspecjalizowany, co jest świadomą decyzją projektową, a nie przypadkowym ograniczeniem.
Warto też pamiętać, że wagi GLM-5 są dostępne na licencji MIT (Hugging Face, 2026), co pozwala na self-hosting. GLM-5.1 jako aktualizacja post-trainingowa prawdopodobnie podąża za tym samym modelem licencjonowania.
Często zadawane pytania
Czy GLM-5.1 jest darmowy?
Nie, dostęp przez API z.ai wymaga GLM Coding Plan (od 10 USD/miesiąc, ok. 40 zł). Wagi bazowego GLM-5 są dostępne na licencji MIT i można je uruchomić samodzielnie (Hugging Face, 2026).
Jak GLM-5.1 wypada na tle Claude Opus?
Na agentic leaderboard GLM-5.1 zajmuje 2. miejsce overall. GLM-5 bazowy osiąga wyniki zbliżone do Claude Opus 4.5 na SWE-bench Verified (77.8), ale w codziennym użytkowaniu Claude zachowuje przewagę w uniwersalności (arxiv.org, 2026).
Czy warto migrować z GLM-5 na GLM-5.1?
Tak, jeśli pracujesz z narzędziami agentowymi typu Claude Code czy Cline. Adaptacyjne skalowanie wnioskowania i lepsze podążanie za instrukcjami dają wymierne przyspieszenie. Jeśli używasz modelu głównie do rozmów — zostań przy GLM-5 (NVIDIA Developer Forums, 2026).
Ile pamięci potrzebuje GLM-5.1?
Model ma 744B parametrów całkowitych z 40B aktywnymi (MoE). Do self-hostingu z kwantyzacją potrzebujesz kilku GPU klasy A100 lub H100. API z.ai eliminuje ten wymóg — model działa w chmurze (z.ai Developer Docs, 2026).
Na jakich benchmarkach GLM-5 osiąga najlepsze wyniki?
GLM-5 prowadzi wśród modeli open-weight na SWE-bench Verified (77.8), Terminal-Bench 2.0 (56.2), BrowseComp i MCP-Atlas. To benchmarks mierzące realistyczne zadania programistyczne, nie tylko generowanie fragmentów kodu (z.ai Developer Docs, 2026).
Podsumowanie
- GLM-5.1 to 744B/40B MoE zoptymalizowany pod zadania agentowe — 2. miejsce na agentic leaderboard
- Adaptacyjne skalowanie wnioskowania eliminuje over-reasoning z GLM-5
- Dostępny od 10 USD/miesiąc w GLM Coding Plan z kompatybilnością z Claude Code, Cline, Cursor
- Kompromis: lekkie regresje w czacie i QA — to model wyspecjalizowany, nie uniwersalny
- Wagi bazowe na licencji MIT — self-hosting jest możliwy
Jeśli pracujesz z AI coding na co dzień, GLM-5.1 to upgrade, który poczujesz w pierwszych minutach. Jeśli dopiero zaczynasz przygodę z modelami kodującymi — sprawdź nasz przewodnik po GLM-5 i Claude Code.