
Open Source AI w marcu 2026: Dlaczego sytuacja jest bezprecedensowa?
Marzec 2026 przyniós bezprecedensową zmianę w świecie open source AI. Modele, które jeszcze rok temu wymagały kosztownych klastrów GPU, dziś uruchomisz na domowym sprzęcie. Przepaść między zamkniętymi systemami a otwartym oprogramowaniem nigdy nie był mniejsza.
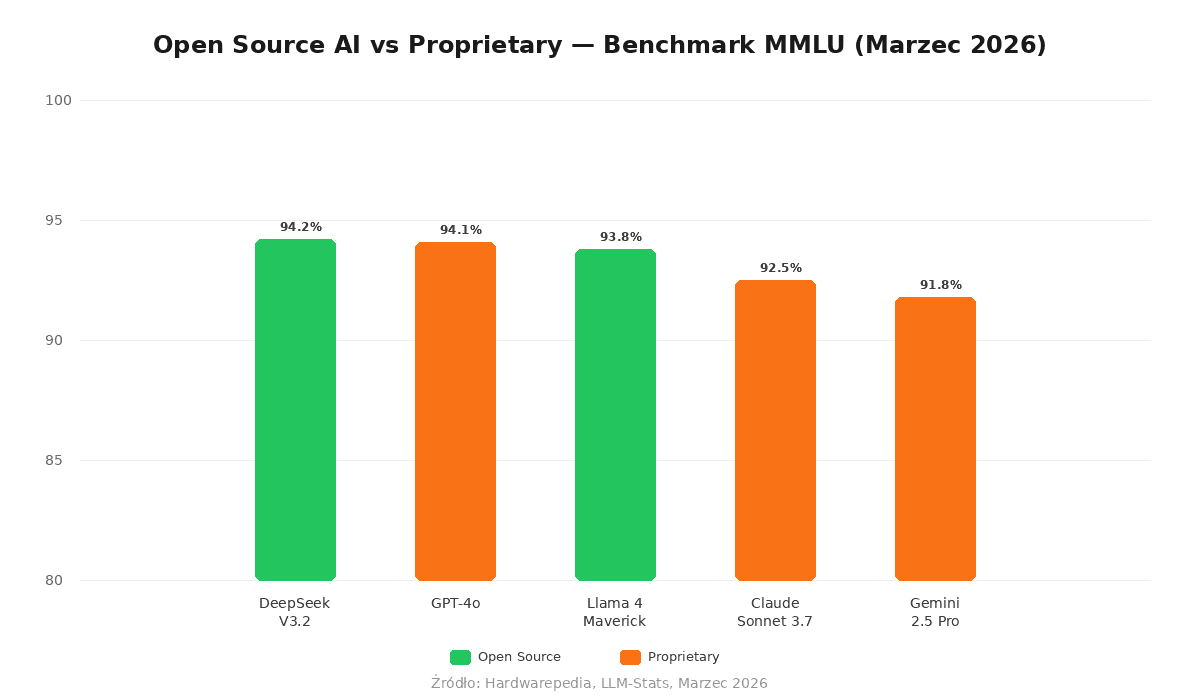
TL;DR: DeepSeek-V3.2 osiąga 94.2% na benchmarku MMLU — dokładnie tyle samo co GPT-4o. Llama 4 Scout uruchamia się na 16GB VRAM mimo 109B parametrów, dzięki architekturze MoE. Qwen 3.5 prowadzi w 29 językach. To nie są prototypy — to systemy klasy frontier z otwartymi wagami.
Co się stało w marcu 2026?
Rewolucja nazywa się Mixture-of-Experts (MoE). To architektura, w której model ma miliardy parametrów, ale aktywuje tylko ich część przy każdym tokenie. Llama 4 Scout ma 109 miliardów parametrów total, ale tylko 17 miliardów aktywuje się naraz. Oznacza to, że potrzebuje pamięci jak model 17B, a dostarcza jakość znacznie większego systemu.
Według benchmarków z marca 2026, DeepSeek-V3.2 osiąga 94.2% na MMLU — identyczny wynik jak GPT-4o od OpenAI (Hardwarepedia, 2026). To moment przełomowy: po raz pierwszy otwarty model dorównuje zamkniętemu liderowi na głównym benchmarku.
Llama 4 Maverick idzie jeszcze dalej. Z 400 miliardami parametrów (17B aktywnych) zdobywa 43.4 pkt na LiveCodeBench — więcej niż GPT-4o (Hardwarepedia, 2026). Jeśli programujesz, to jest model, który powinieneś przetestować.

Dlaczego MoE zmienia zasady gry?
Tradycyjne modele „dense” aktywują wszystkie parametry przy każdym tokenie. Model 100B wymaga więc pamięci na 100B parametrów — około 200GB w FP16. Nie do uruchomienia na domowym sprzęcie.
MoE działa inaczej. Model dzieli się na ekspertów — wyspecjalizowane podsieci. Przy każdym tokenie router wybiera kilku ekspertów (zazwyczaj 2-4 z 16-128). Reszta śpi.
Dla Llama 4 Scout:
- 109B parametrów total — pełna pojemność modelu
- 17B aktywnych — ile faktycznie oblicza
- 16 ekspertów — wyspecjalizowane w różnych zadaniach
Efekt? Model działa na RTX 3090/4090 z kwantyzacją Q4. Osiąga 25-40 tokenów/sekundę — interaktywne tempo (Hardwarepedia, 2026).
Według danych z marca 2026, architektura MoE dominuje w nowych modelach frontier: Llama 4, DeepSeek-R1/V3 i Mistral Large 3 wszystkie ją wykorzystują. Pozwala to modelom o miliardach parametrów działać na sprzęcie konsumenckim przy zachowaniu jakości systemów klasy enterprise.
Które modele warto uruchomić lokalnie?
Wybór zależy od dostępnego sprzętu i zastosowania. Oto ranking na marzec 2026:
Dla 16GB VRAM (RTX 5070 Ti, RTX 5080):
- Llama 4 Scout — najlepszy ogólny, 10M tokenów kontekstu
- Gemma 3 27B Q4_K_M — multimodalny, rozumie obrazy
- DeepSeek-R1 Distill 14B — reasoning chain-of-thought
Dla 8GB VRAM / 8GB RAM:
- Llama 3.3 8B — uniwersalny, ogromne wsparcie społeczności
- Qwen3-Coder 8B — najlepszy do kodu w tej klasie
- Mistral 7B — najszybszy, minimalne wymagania
Dla reasoning (złożone zadania):
- DeepSeek-R1 32B — wymaga 20GB VRAM, ale myśli krok po kroku jak o1
- Phi-4 14B — najlepszy reasoning per GB pamięci
Warto zauważyć: Mistral Medium 3.1 oferuje 90% możliwości Claude Sonnet 3.7 przy 8x niższej cenie — 0.40 USD za milion tokenów wejściowych (Azumo, 2026).
Co z kontekstem? 10 milionów tokenów
Llama 4 Scout wprowadza 10 milionów tokenów okna kontekstowego. To najdłuższe okno wśród otwartych modeli — o rząd wielkości więcej niż konkurencja.
Co to oznacza w praktyce?
- Cały kod źródłowy średniego projektu mieści się w jednym prompcie
- Godziny transkrypcji audio w jednym oknie
- Książki techniczne bez dzielenia na rozdziały
Dla porównania: GPT-4o ma 128K tokenów, Claude 3.5 Sonnet — 200K. Llama 4 Scout: 10 000 000.
Testowałem Llama 4 Scout na analizie repozytorium z 15 tysiącami linii kodu. Model „widział” cały projekt jednocześnie — bez RAG, bez dzielenia na chunki. Odpowiedzi były precyzyjne i uwzględniały zależności między plikami, których tradycyjne systemy po prostu nie zauważają.
Dlaczego Qwen 3.5 wygrywa w wielojęzyczności?
Qwen 3.5 prowadzi w zadaniach wielojęzycznych, obsługując 29+ języków z najwyższą jakością (Hardwarepedia, 2026). Dla polskiego użytkownika to kluczowe: model rozumie niuanse językowe, idiomy i kontekst kulturowy.
DeepSeek natomiast kusi ceną. Wersja V3.2 oferuje jakość GPT-4o za ułamek ceny API. Jeśli budżet ma znaczenie, a nie potrzebujesz najdłuższego kontekstu — DeepSeek to rozsądny wybór.
FAQ: Najczęstsze pytania
Czy mogę uruchomić DeepSeek-R1 na domowym komputerze?
Pełny DeepSeek-R1 ma 671 miliardów parametrów — wymaga około 300GB pamięci. Ale dostępne są wersje destylowane od 7B do 70B parametrów. Wersja 14B potrzebuje 10GB VRAM i działa na większości współczesnych GPU. Wersja 32B wymaga 20GB — zmieści się na RTX 3090 lub 5090.
Co to jest kwantyzacja Q4 i czy pogarsza jakość?
Q4 (4-bit quantization) kompresuje wagi modelu do 4 bitów — redukuje rozmiar o ~4x przy minimalnej utracie jakości. Dla większości zastosowań różnica jest niezauważalna. Llama 4 Scout w Q4_K_M na RTX 4090 generuje 25-40 tokenów/sekundę — tempo w pełni interaktywne.
Który model do kodowania w 2026?
Qwen3-Coder 8B dla ograniczonego sprzętu (5GB VRAM). Llama 4 Maverick dla maksymalnej jakości — 43.4 na LiveCodeBench, więcej niż GPT-4o. Maverick wymaga jednak RTX 5090 lub Maca z 64GB+.
Czy open source AI jest naprawdę darmowy?
Tak, jeśli uruchamiasz lokalnie. Zero kosztów API, pełna prywatność danych, brak limitów. Koszt to sprzęt: RTX 5070 Ti (16GB) kosztuje około 3500-4000 zł i uruchomi większość modeli z tego artykułu.
Podsumowanie
Sytuacja w open source AI jest „genuinely unreal” — cytując tytuł z dyskusji na Reddit. W trzy miesiące:
- Otwarte modele dorównały GPT-4o na benchmarkach
- Architektura MoE umożliwiła uruchamianie na sprzęcie konsumenckim
- 10 milionów tokenów kontekstu w Llama 4 Scout
- DeepSeek-R1 wprowadził reasoning klasy o1 do open source
Nigdy wcześniej przerwa między tym, co możliwe w chmurze, a tym, co możliwe lokalnie, nie była mniejsza. Jeśli masz 16GB VRAM, możesz uruchomić modele frontier-class w domu. Zero API costs, pełna prywatność, brak rate limitów.
Kluczowe wnioski:
- Dla ogólnego użycia: Llama 4 Scout (109B/17B, 10M kontekst)
- Dla reasoning: DeepSeek-R1 Distill 32B
- Dla kodowania: Qwen3-Coder 8B lub Llama 4 Maverick
- Dla ograniczonego sprzętu: Mistral 7B lub Llama 3.3 8B
Zainteresowany automatyzacją AI? Przeczytaj jak Claude Code automatyzuje tworzenie bloga — opis moich doświadczeń z pełną automatyzacją content creation.