
Google TurboQuant: 6x kompresja pamięci AI wstrząsa rynkiem chipów
Gdy w poniedziałek Google Research opublikowało artykuł o TurboQuant, niewielu spodziewało się, że do czwartku akcje największych producentów pamięci na świecie spadną o 6%. Algorytm kompresujący pamięć modeli AI sześciokrotnie, bez utraty jakości, wywołał falę wyprzedaży na giełdach od Seulu po Nowy Jork. CEO Cloudflare Matthew Prince nazwał to „Google’owskim DeepSeekiem”.
TL;DR: Google TurboQuant redukuje pamięć potrzebną do uruchamiania LLM 6x, jednocześnie przyspieszając działanie 8x — wszystko bez utraty dokładności. Technika oparta na PolarQuant i Quantized Johnson-Lindenstrauss zostanie zaprezentowana na ICLR 2026 w kwietniu. Akcje SK Hynix, Samsunga i Microna spadły do 6% w reakcji na wiadomość.
Czym jest TurboQuant i jak działa kompresja 6x?
TurboQuant to zbiór algorytmów kwantyzacji opracowanych przez Google Research, które drastycznie zmniejszają ślad pamięciowy dużych modeli językowych (LLM). Kluczowym celem jest tzw. key-value cache — bufor przechowujący wcześniej obliczone wyniki, który Google porównuje do „cyfrowej ściągawki”. Im dłuższa rozmowa z modelem, tym większy cache, a to wymaga gigabajtów drogiej pamięci HBM.
Według Google Research TurboQuant osiąga co najmniej 6-krotną redukcję pamięci KV cache przy jednoczesnym 8-krotnym przyspieszeniu wnioskowania (Google Research, marzec 2026). Co kluczowe — dokładność modelu pozostaje na niezmienionym poziomie. Testy przeprowadzono na modelach Gemma i Mistral na pięciu benchmarkach: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER i L-Eval.
Jak to możliwe? Tradycyjna kwantyzacja zamienia precyzyjne wartości dziesiętne na mniej dokładne liczby całkowite, co oszczędza pamięć, ale degraduje jakość. TurboQuant podchodzi do problemu inaczej — wykorzystuje matematyczną transformację współrzędnych, która zachowuje istotę danych przy znacznie mniejszym rozmiarze.
PolarQuant — matematyczny trik, który zmienia wszystko
Sercem TurboQuant jest metoda PolarQuant. Standardowo wektory w modelach AI są kodowane we współrzędnych Kartezjańskich (x, y, z). PolarQuant zamienia je na współrzędne biegunowe — redukując każdy wektor do dwóch informacji: promienia (siła danych) i kierunku (znaczenie danych).
Google podaje trafną analogię: zamiast mówić „idź 3 przecznice na wschód i 4 na północ”, wystarczy powiedzieć „idź 5 przecznic pod kątem 37 stopni”. Efekt? Te same informacje zajmują mniej miejsca, a system nie musi wykonywać kosztownych operacji normalizacji danych.
Drugi krok to Quantized Johnson-Lindenstrauss (QJL) — jednobitowa warstwa korekcji błędów, która niweluje niedokładności wprowadzone przez PolarQuant. Każdy wektor residualny jest redukowany do pojedynczego bita (+1 lub -1), co zachowuje istotę informacji przy minimalnym koszcie pamięciowym. Obie metody zostaną zaprezentowane na konferencji ICLR 2026 w kwietniu.
Dlaczego akcje producentów pamięci spadły?
Wiadomość o TurboQuant wywołała natychmiastową reakcję na rynkach finansowych. W czwartek 26 marca akcje SK Hynix spadły o 6%, Samsunga o 4,9%, a japońska Kioxia straciła niemal 6%. W Stanach Zjednoczonych Micron i SanDisk również zanotowały spadki (CNBC, marzec 2026).
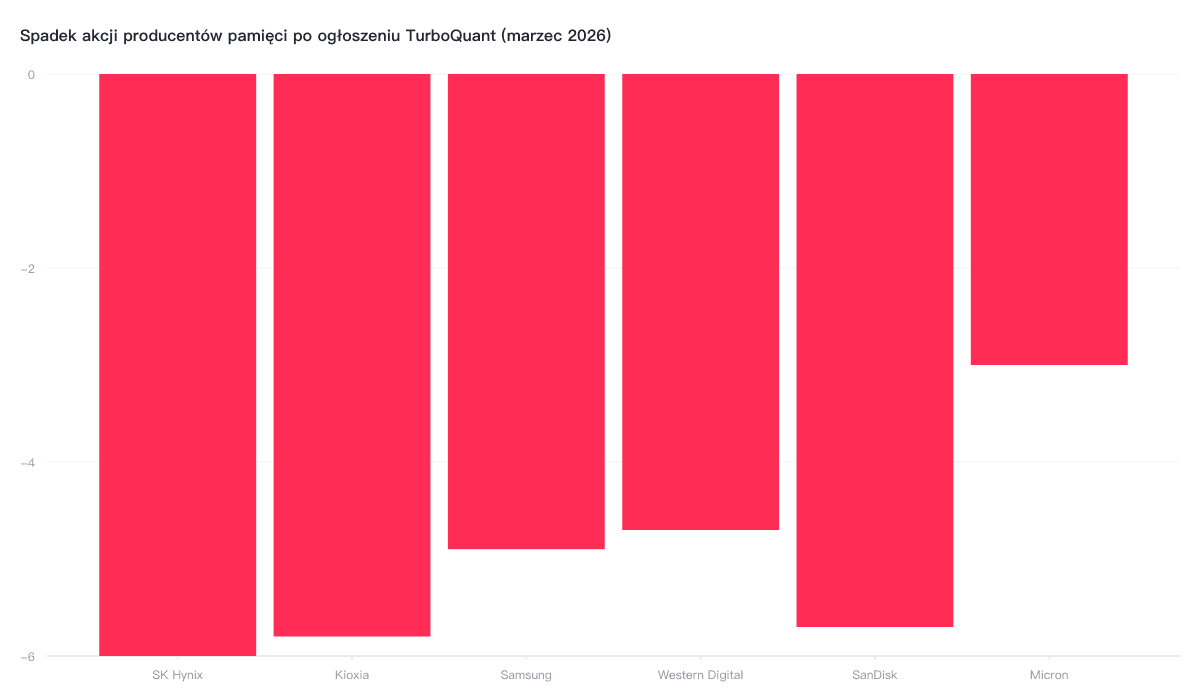
Kontekst jest ważny: w ciągu poprzedniego roku Samsung wzrósł o niemal 200%, a Micron i SK Hynix o ponad 300%. Analitycy z Quilter Cheviot wskazują, że wyprzedaż to przede wszystkim realizacja zysków, a nie fundamentalna zmiana perspektyw. „Pamięć to sektor wysoce cykliczny, a inwestorzy szukali powodów do de-riskingu” — zauważa Ben Barringer, szef badań technologicznych w Quilter Cheviot.
CEO Cloudflare Matthew Prince określił TurboQuant mianem „Google’owskiego DeepSeeka”, nawiązując do ubiegłorocznego szoku wywołanego przez chińską firmę DeepSeek, który doprowadził do masowej wyprzedaży na NASDAQ. Tego typu przełomy potwierdzają trend, o którym pisaliśmy w kontekście końca ery monopolu AI i transformacji modeli LLM w towar — efektywność algorytmiczna drastycznie obniża bariery wejścia.
TurboQuant vs DeepSeek — historia się powtarza?
Porównanie z DeepSeek jest naturalne, ale mechanizmy obu przełomów różnią się zasadniczo. DeepSeek pokazał, że można trenować potężne modele za ułamek kosztu konkurencji. TurboQuant adresuje inne wąskie gardło — koszt wnioskowania, czyli uruchamiania już wytrenowanych modeli.
Kluczowa różnica leży w tym, co kompresują. DeepSeek zoptymalizował proces treningu — mniej GPU potrzebnych do stworzenia modelu. TurboQuant kompresuje pamięć runtime’ową — mniej RAM potrzebnych do jego działania. To dwa różne problemy, ale oba prowadzą do tego samego wniosku: AI staje się tańsze i bardziej dostępne.
Dla użytkownika końcowego to doskonała wiadomość. Modele, które dziś wymagają serwerów z wieloma GPU H100 po 30 000 USD (ok. 120 000 zł) za sztukę, mogą wkrótce działać na znacznie tańszym sprzęcie. To otwiera drogę do lokalnego uruchamiania zaawansowanych LLM na komputerach osobistych i urządzeniach mobilnych. Temat inwestycji w chipy AI przybliżyliśmy w artykule o 73-miliardowej inwestycji Samsunga w półprzewodniki — TurboQuant to kolejny czynnik zmieniający kalkulację takich inwestycji.
Co to oznacza dla przyszłości AI?
Wbrew obawom inwestorów, większość analityków uważa, że TurboQuant nie zagrozi długoterminowemu popytowi na pamięć AI. Paradoksalnie, tańsze uruchamianie modeli może zwiększyć całkowite zapotrzebowanie na chipy — poprzez efekt Jevonsa, znany w ekonomii od XIX wieku.
Jeśli koszty uruchamiania LLM spadają 6x, więcej firm może sobie pozwolić na wdrożenie AI. Więcej wdrożeń oznacza więcej serwerów, a więcej serwerów — więcej pamięci. Forbes zauważa, że TurboQuant może paradoksalnie zwiększyć popyt na pamięć AI w długim terminie (Forbes, marzec 2026).
Obserwuję trend demokratyzacji AI od początku 2025 roku. Każdy algorytmiczny przełom — od Flash Attention po Mixture of Experts — początkowo budzi obawy o sprzęt, a ostatecznie zwiększa całkowity popyt. TurboQuant wpisuje się w ten sam schemat: krótkoterminowy szok, długoterminowy wzrost.
Terminarz jest jasny: Google zaprezentuje szczegóły techniczne na ICLR 2026 w kwietniu. Jeśli wyniki potwierdzą się w środowiskach produkcyjnych, czekamy na wdrożenia w Gemini, Vertex AI i usługach chmurowych Google Cloud.
Najczęściej zadawane pytania
Czy TurboQuant faktycznie nie obniża jakości modelu?
Tak — według testów Google na benchmarkach LongBench, Needle In A Haystack i RULER, TurboQuant osiąga identyczne wyniki jak pełnoprecyzyjne modele Gemma i Mistral. Kluczem jest dwuetapowa kompresja: PolarQuant zachowuje główne informacje, a QJL eliminuje residualne błędy.
Kiedy TurboQuant będzie dostępny w produktach Google?
Google ogłosiło prezentację na ICLR 2026 w kwietniu. Historycznie, technologie badawcze Google trafiają do produktów w ciągu 3-6 miesięcy od publikacji — najpierw Vertex AI, potem Gemini.
Czy to oznacza spadek cen pamięci RAM dla konsumentów?
Nie bezpośrednio. TurboQuant dotyczy pamięci HBM używanej w serwerach AI. Pamięć DDR5 dla konsumentów podąża własnym cyklem cenowym, choć w długim terminie efektywniejsze AI może zmniejszyć presję na produkcję.
Jak TurboQuant wpłynie na rynek GPU?
Krótkoterminowo — presja na akcje producentów pamięci. Długoterminowo — niższe wymagania pamięciowe oznaczają, że więcej zadań AI będzie mogło działać na tańszych GPU, co może rozszerzyć rynek zamiast go kurczyć.
Czy inne firmy pracują nad podobnymi rozwiązaniami?
Tak — KIVI, KVQuant i inne metody kwantyzacji KV cache istniały wcześniej, ale TurboQuant osiąga lepsze rezultaty. Wyróżnia go połączenie PolarQuant z QJL, które daje bezstratną kompresję, podczas gdy konkurencyjne metody zawsze degradują jakość.
Podsumowanie
Google TurboQuant to więcej niż kolejny algorytm kompresji. To dowód, że postęp w AI nie polega wyłącznie na budowaniu większych modeli — równie ważna jest ich optymalizacja. 6-krotna redukcja pamięci bez utraty jakości to wynik, który zmienia kalkulację kosztów dla każdej firmy planującej wdrożenie LLM.
Co to oznacza w praktyce? Modele, które dziś wymagają klastra GPU, za kilka miesięcy mogą działać na pojedynczej karcie. A dla inwestorów w pamięć AI — krótkoterminowy szok, ale długoterminowo więcej AI oznacza więcej chipów. Efekt Jevonsa działa.
- TurboQuant kompresuje KV cache LLM 6x przy 8x przyspieszeniu
- PolarQuant + QJL — dwuetapowa bezstratna kompresja
- Akcje producentów pamięci spadły do 6% po ogłoszeniu
- Prezentacja na ICLR 2026 w kwietniu
- Analitycy: to profit-taking, nie zmiana fundamentów